السلام عليكم ورحمة الله وبركاته احباب مدونة اقرا معي وتعلم علىالانترنت مرحبا بكم في دروس المعالجات الدقيقة تعتبر هذه التدوينات والتي نعتبرها سلسلة من الدروس في الدوائر
الموائمة computer
interface
والمعالجات الدقيقة CPU ، تفيد
وبشكل كبير طلاب هندسة الحاسوب ، كذلك علوم الحاسوب ، حيث وانها من ضمن مقررهم
الدوائر الموائمة (computer interface) ذكرنا في التدوينات الماضية بعض تاريخ عائلات
المعالجات
CPU – computer interface ، ثم
تحدثنا عن معالجات risc and cisc ، وذكرنا
الفرق بين معالجات 4CISC و معالجات RISC ، ( difference between risc and cisc processor)
وهذا روابط التدوينات السابقة :
الدرس الاول : بحث في تاريخ عائلات المعالجات CPU – computer interface
الدرس الثاني: risc and cisc processor - computer interface
اليوم نواصل مسيرنا في سلسلة دروس الدوائر الموئمة ونتعرف مع بعض على
مبدأ المعالجة التواردية pipelining
.
تنفذ
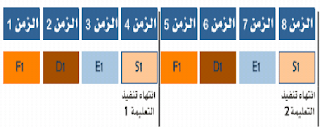
المعالجات التقليدية تعليمة واحدة بآن واحد (لذلك تُسمى بالمعالجات السلمية scalar processor) أي لا يبدأ المعالج تنفيذ التعليمة التالية إلا بعد الانتهاء تمامًا من تنفيذ التعليمة الحالية.
بفرض
أن تنفيذ تعليمة يحتاج إلى أربع عمليات أساسية: جلب،
فك ترميز، تنفيذ وتخزين، وبفرض أن كل عملية تنجز خلال وحدة زمنية، فيحتاج تنفيذ تعليمة واحدة إلى أربعة وحدات زمنية ويحتاج تنفيذ تعليمتين إلى 8 وحدات زمنية.
نذكر
من
المعالجات
التي
تتبنى
هذا
البنيان الا وهو :
المعالج 8085

إذا
احتوى المعالج على عدة وحدات متخصصة:
واحدة
لجلب التعليمة وأخرى لفك ترميزها وثالثة لتنفيذها ورابعة لتخزين المعطيات، عندئذ يمكن تنفيذ أكثر من تعليمة بآن واحد.
فبينما تعمل
وحدة الجلب على جلب تعليمة جديدة تعمل وحدة الفك على فك التعليمة التي أنهت وحدة الجلب جلبها من الذاكرة، وتعمل وحدة التنفيذ على تنفيذ التعليمة التي أنهت وحدة فك التعليمة من فكها أو تحليلها، وتعمل وحدة التخزين على تخزين ناتج العملية السابقة. تسمى هذه التقنية بالتوارد Pipelining لأن كل وحدة تخصصية تُورد نتائجها إلى الوحدة التي تليها عند إنهاء مهمتها عبر قناة نُسميها قناة المواردة Pipeline

نجد
من المخطط السابق أن التعليمة الأولى قد احتاجت إلى أربعة وحدات زمنية لإنهاء تنفيذها، كما هو الحال في المعالج التقليدي، في حين احتاج تنفيذ الثانية فقط إلى وحدة زمنية واحدة وكذلك التعليمة الثالثة وهكذا ..
نستنتج
أن وجود الوحدات التخصصية أدى إلى إنقاص زمن المعالجة تقريبًا إلى الربع، ما عدا التعليمة الأولى التي بقي زمن تنفيذها بدون تغيير.
نذكر
من
المعالجات
التي
تستخدم
في
تصميمها
مبدأ
التوارد
معالجات AVR والمتحكمات الصغرية من PIC ومعالج بنتيوم 4 .
مع
أن مبدأ التوارد يسمح بإنقاص زمن تنفيذ البرنامج، فإن وجود بعض الصعوبات تجعل أداءه أقل من النحو المرغوب فيه.
فمن
ناحية، نجد أن مزامنة عمل الوحدات ليس بالأمر السهل بسبب عدم استغراق جميع الوحدات المدة نفسها لإنهاء عمل كل منها، فمثلا نجد أن الزمن اللازم لتنفيذ تعليمة يكون عادة أكبر من زمن جلب تعليمة. ومن
ناحية أخرى، تُغير تعليمات القفز من تتابع تنفيذ التعليمات، مما يستدعي إفراغ قناة المواردة ثم ملأها مجددًا بعد إنجاز عملية القفز، وهذا يبطئ سرعة تنفيذ البرنامج.
نكتفي بهذا ونلتقي في التدوين القادم او الدرس الرابع بعنوان
بنية المعالجات السُّلمية الفائقة Superscalar.
عزيزنا الزائر إن كانت هذه اول زيارة لك لمدونتنا لا تنسى الاشتراك
فيها عبر بريدك الالكتروني ليصلك كل جديد او قم بالإعجاب بصفحتنا على الفيس بوك في
يسار الصفحة ....
{kind=link}
إرسال تعليق
لا تبخل علينا باقتراحك او قم بمشاركة الموضوع ليستفيد الاخرين ايضاً شكرا لزيارتك عزيزي الزائر